LangChain4j 检索增强生成 (RAG) 教程
在本文中,我们将探讨以下内容:
了解检索增强生成 (RAG) 的需求。
了解 EmbeddingModel、EmbeddingStore、DocumentLoaders、EmbeddingStoreIngestor。
使用不同的 EmbeddingModels 和 EmbeddingStores。
将数据引入 EmbeddingStore。
使用 EmbeddingStore 中的数据查询 LLM。
示例代码存储库
可以在 GitHub 存储库中找到本文的示例代码
LangChain4j 教程系列
您可以查看本系列中的其他文章:
了解检索增强生成 (RAG) 的需求
在之前的文章中,我们已经了解了如何提出问题并从 AI 模型中获得响应。 但是,在为您的企业构建 AI 驱动的应用程序时,AI 模型没有业务数据的上下文。
您的企业可能会将结构化数据存储在关系数据库中,将非结构化数据存储在 NoSQL 数据库中,甚至存储在文件中。 您将能够有效地使用 SQL 查询关系数据库,使用它们的查询语言查询 NoSQL 数据库。 您还可以使用 Elasticsearch、Solr 等全文搜索引擎来查询非结构化数据。
但是,您可能希望使用具有语义含义的自然语言检索数据。
例如,“我喜欢 Java 编程语言”和“Java 始终是我的首选语言”具有相同的语义含义,但使用不同的词。 尝试使用确切的单词检索数据可能无效。
这就是嵌入发挥作用的地方。嵌入是单词、句子或文档的向量表示形式。 您可以使用这些嵌入通过自然语言检索数据。
您可以将结构化和非结构化数据转换为嵌入,并将它们存储在 EmbeddingStore 中。 然后,可以使用自然语言查询 EmbeddingStore 并检索相关数据。 然后,您可以查询传递相关数据的 AI 模型以获取响应。
检索增强生成 (RAG) 是优化 LLM 输出的过程, 在生成响应之前,除了训练数据之外,还使用其他知识库。
了解 EmbeddingModel、EmbeddingStore、EmbeddingStoreIngestor
首先,让我们了解 RAG 中涉及的各种组件。
嵌入模型
EmbeddingModel 是一种可以将单词、句子或文档转换为嵌入的模型。 嵌入是单词、句子或文档的向量表示形式。
例如,单词“Apple”可以表示为向量。 一句话“我爱苹果”可以表示为向量。[0.1, 0.2, 0.3, 0.4, 0.5][0.1, 10.3, -10.2, 90.3, 2.4, -0.5]
LangChain4j 提供了一个接口,支持各种实现:EmbeddingModel
AllMiniLmL6V2EmbeddingModel:在 Java 应用程序进程中运行的嵌入模型
OpenAiEmbeddingModel:表示 OpenAI 嵌入模型
AzureOpenAiEmbeddingModel:表示 Azure OpenAI 嵌入模型
OllamaEmbeddingModel:表示任何 Ollama 支持的模型嵌入模型
VertexAiEmbeddingModel:表示 Google 的 Vertex AI 嵌入模型
HuggingFaceEmbeddingModel:表示 HuggingFace 嵌入模型
我们可以创建 EmbeddingModel 的实例,如下所示:
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
// or
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.withApiKey("demo");
// or
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama2")
.build();
嵌入商店
EmbeddingStore 是可以存储单词、句子或文档嵌入的数据存储。 市面上有Neo4j、ElasticSearch、Pgvector、Redis、Chroma、Milvus等各种Vector数据库,可以存储嵌入内容。
LangChain4j 提供了一个接口 EmbeddingStore 并支持各种实现:
InMemoryEmbeddingStore
Neo4jEmbeddingStore
OpenSearchEmbeddingStore
ChromaEmbedding商店
PineconeEmbeddingStore
MilvusContainer
以及更多...
您可以创建 EmbeddingStore 的实例,如下所示:
EmbeddingStore embeddingStore = new InMemoryEmbeddingStore();
// or
EmbeddingStore embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl("http://localhost:8000")
.collectionName("my-collection")
.build();
// similarly, you can use any other implementation
DocumentLoaders
DocumentLoader 是一个组件,可以将来自各种来源(如文件、URL 等)的数据加载到文档中。
LangChain4j 提供了各种 DocumentLoader 实现:
FileSystemDocumentLoader:将数据从文件加载到文档中
UrlDocumentLoader:将数据从 URL 加载到文档中
Path path = Paths.get("/path/to/some/file.txt");
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
您可以按如下方式从 Web URL 加载文档:
URL url = new URL("https://www.sivalabs.in/about-me/");
Document htmlDocument = UrlDocumentLoader.load(url, new TextDocumentParser());
HtmlTextExtractor transformer = new HtmlTextExtractor(null, null, true);
Document document = transformer.transform(htmlDocument);
EmbeddingStoreIngestor
EmbeddingStoreIngestor 是可以将数据引入 EmbeddingStore 的组件。
我们可以使用 EmbeddingModel 将文本数据转换为嵌入并将其存储在 一个 EmbeddingStore,如下所示:
TextSegment segment = TextSegment.from("your text goes here");
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment);
我们的数据可以是各种文件格式,如 TXT、CSV、PDF、网页等。 我们可以将文件中的数据加载到文档中,将文档拆分为文本段, 将文本段转换为嵌入,并将它们存储在 EmbeddingStore 中。
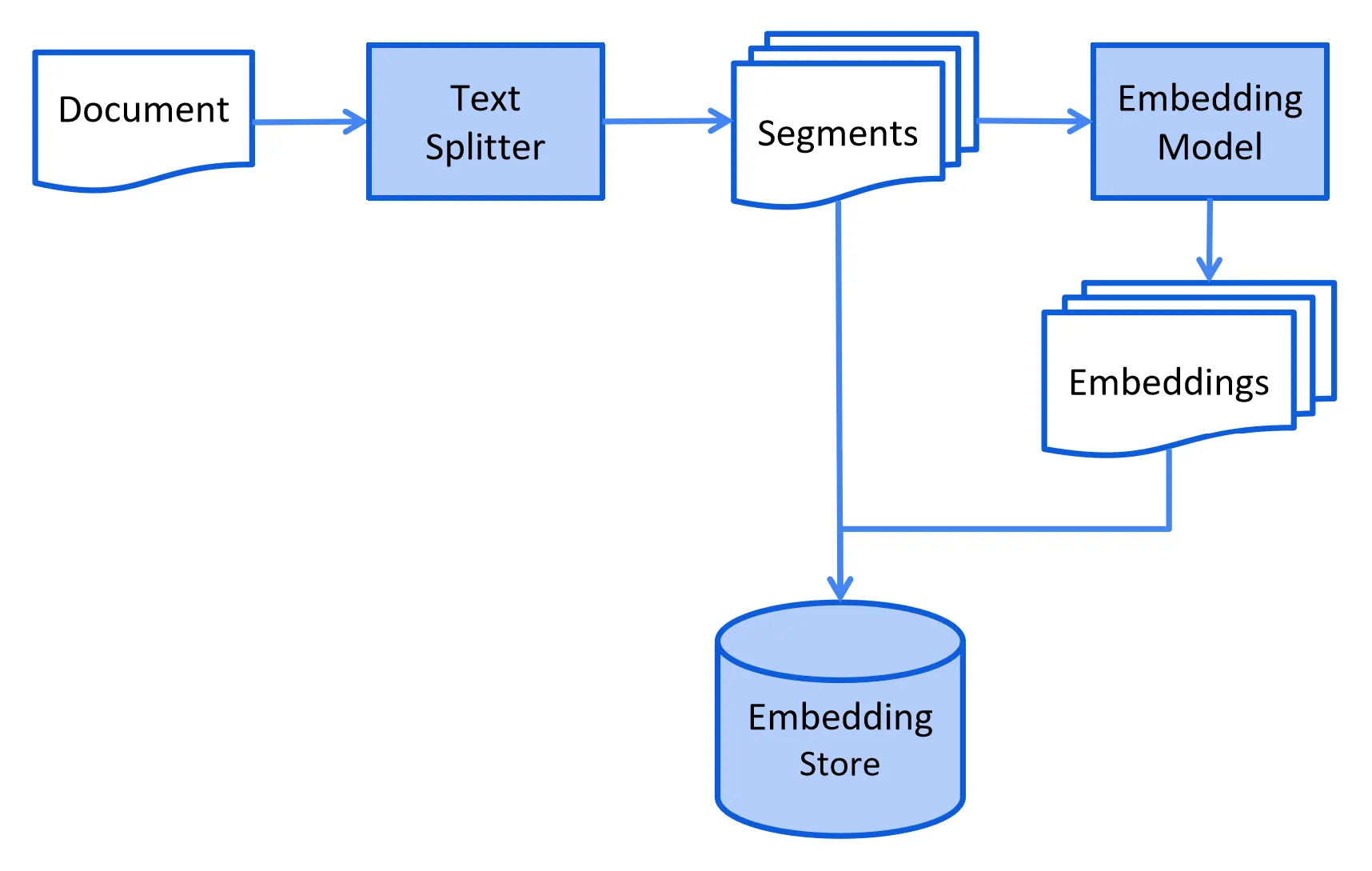
来源: https://docs.langchain4j.dev/tutorials/rag
让我们创建一个示例数据文件siva.txt在 src/main/resources 文件夹中 包含以下内容:
Siva, born on 25 June 1983, is a software architect working in India.
He started his career as a Java developer on 26 Oct 2006 and worked with other languages like Kotlin, Go, JavaScript, Python too.
He authored "Beginning Spring Boot 3" book with Apress Publishers.
He has also written "PrimeFaces Beginners Guide" and "Java Persistence with MyBatis 3" books with PacktPub.
现在我们可以从文件中加载数据并将嵌入存储在 EmbeddingStore 中,如下所示:
URL fileUrl = RAGDemo.class.getResource("/siva.txt");
Path path = Paths.get(fileUrl.toURI());
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(600, 0);
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
还可以使用 EmbeddingStoreIngestor 将数据引入 EmbeddingStore 中,如下所示:
URL fileUrl = RAGDemo.class.getResource("/siva.txt");
Path path = Paths.get(fileUrl.toURI());
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(600, 0);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
使用来自 EmbeddingStore 的数据查询 LLM
将数据引入 EmbeddingStore 后,我们可以使用自然语言查询 EmbeddingStore 并检索相关数据。 然后,我们可以查询传递相关数据的 AI 模型以获得响应。
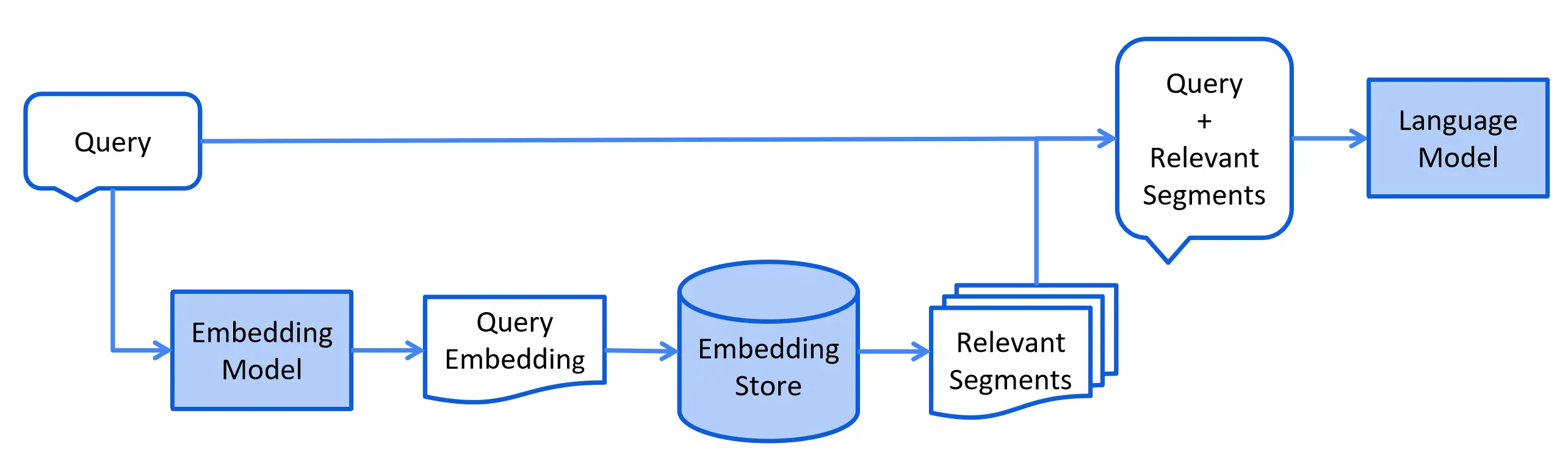
来源: https://docs.langchain4j.dev/tutorials/rag
Embedding queryEmbedding = embeddingModel.embed("Tell me about Siva?").content();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.findRelevant(queryEmbedding, 1);
EmbeddingMatch<TextSegment> embeddingMatch = relevant.getFirst();
String information = embeddingMatch.embedded().text();
Prompt prompt = PromptTemplate.from("""
Tell me about {{name}}?
Use the following information to answer the question:
{{information}}
""").apply(Map.of("name", "Siva","information", information));
String answer = model.generate(prompt.toUserMessage()).content().text();
System.out.println("Answer:"+answer);
// Output:
// Answer:Siva is a software architect born on 25 June 1983 in India.
// He began his career as a Java developer on 26 Oct 2006 and has since worked with other languages
// such as Kotlin, Go, JavaScript, and Python. Siva has authored several books including
// "Beginning Spring Boot 3" with Apress Publishers, "PrimeFaces Beginners Guide" and
// "Java Persistence with MyBatis 3" with PacktPub.
警告
需要注意的一件事是将传递给 AI 模型的相关数据的长度。 AI 模型可能对它们一次可以处理的代币数量有限制。 此外,LLM 可能会根据处理的令牌数量向您收费。
虽然这有效,但我们可以使用带有 ContentRetriever 的 AiServices 来简化这一点,如下所示:
record Person(String name,
LocalDate dateOfBirth,
int experienceInYears,
List<String> books) {
}
interface PersonDataExtractor {
@UserMessage("Get information about {{it}} as of {{current_date}}")
Person getInfoAbout(String name);
}
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(1)
.build();
PersonDataExtractor extractor =
AiServices.builder(PersonDataExtractor.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.build();
Person person = extractor.getInfoAbout("Siva");
System.out.println(person);
// Output:
// Person[name=Siva, dateOfBirth=1983-06-25, experienceInYears=17, books=[Beginning Spring Boot 3, PrimeFaces Beginners Guide, Java Persistence with MyBatis 3]]
我们创建了一个 EmbeddingStoreContentRetriever 的实例,并通过传递 ContentRetriever 使用 AiServices 获取 PersonDataExtractor 的实例。
现在,当我们可以调用 getInfoAbout() 方法时,它将从 EmbeddingStore 获取相关数据并将其传递给 AI 模型以获取响应。
结论
在本文中,我们已经了解了如何使用 RAG 使用我们自己的数据来增强 LLM 功能。
要了解 LangChain4j 提供的更多高级 RAG 功能,请参阅 https://docs.langchain4j.dev/tutorials/rag。