k8s源码解析(5)--调度流程
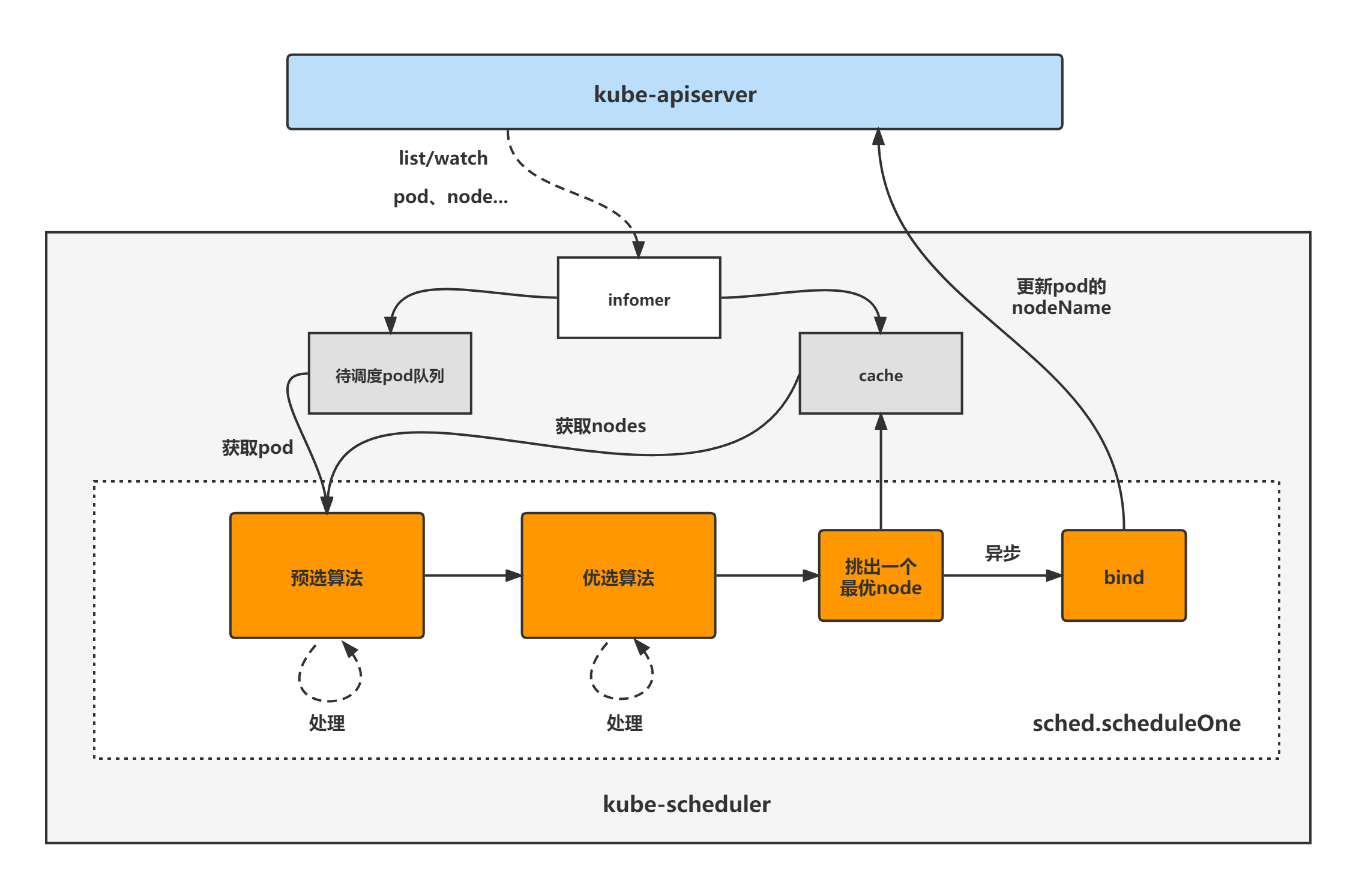
调度流程
当api-server处理完一个pod的创建请求后,此时可以通过kubectl把pod get出来,但是pod的状态是Pending。在这个Pod能运行在节点上之前,它还需要经过scheduler的调度,为这个pod选择合适的节点运行。
1. 定时调用
//pkg/scheduler/scheduler.go
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
//sched.scheduleOne 核心逻辑,从未调度的pod列表中取出一个pod 选择一个node
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
// Run starts the goroutine to pump from podBackoffQ to activeQ
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
sched.SchedulingQueue.Run():会启动两个定时go routine,分别为flushBackoffQCompleted和flushUnschedulablePodsLeftover
flushBackoffQCompleted: 每1 second执行一次,将backoffQ中的pod移动到activeQ中
flushUnschedulablePodsLeftover: 每30 seconde执行一次,将UnschedulablePods中的pod移动到activeQ或backoffQ中 (如果pod仍然在backoff time内则会被放到backoffQ中)
//不断的从activeQ中取出Pod进行调度
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
2. 调度流程
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne(ctx context.Context) {
//从activeQ中取出一个Pod进行调度
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
//根据pod中的schedule name选择一个对应的framework来执行调度
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
//执行调度
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
if err != nil {
// SchedulePod() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
var nominatingInfo *framework.NominatingInfo
reason := v1.PodReasonUnschedulable
//错误为FitError时,执行Preempt抢占
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle.
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
fitError.Diagnosis.PostFilterMsg = status.Message()
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else if err == ErrNoNodesAvailable {
nominatingInfo = clearNominatedNode
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else {
nominatingInfo = clearNominatedNode
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
sched.handleSchedulingFailure(fwk, podInfo, err, reason, nominatingInfo)
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
//assumedPod写入缓存中 bind结束后清除
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
sched.handleSchedulingFailure(fwk, assumedPodInfo, err, SchedulerError, clearNominatedNode)
return
}
// Run the Reserve method of reserve plugins.
if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.handleSchedulingFailure(fwk, assumedPodInfo, sts.AsError(), SchedulerError, clearNominatedNode)
return
}
// Run "permit" plugins.
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if runPermitStatus.Code() != framework.Wait && !runPermitStatus.IsSuccess() {
var reason string
if runPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// One of the plugins returned status different than success or wait.
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.handleSchedulingFailure(fwk, assumedPodInfo, runPermitStatus.AsError(), reason, clearNominatedNode)
return
}
// At the end of a successful scheduling cycle, pop and move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
//为了提升调度器的调度性能,bind阶段通过一个go routine来异步的完成
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()
//在上面的PermitPlugin阶段可能会使得pod处于waiting状态,此时则是等待waiting状态的结束
waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
var reason string
if waitOnPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
// Avoid moving the assumed Pod itself as it's always Unschedulable.
// It's intentional to "defer" this operation; otherwise MoveAllToActiveOrBackoffQueue() would
// update `q.moveRequest` and thus move the assumed pod to backoffQ anyways.
defer sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, func(pod *v1.Pod) bool {
return assumedPod.UID != pod.UID
})
}
sched.handleSchedulingFailure(fwk, assumedPodInfo, waitOnPermitStatus.AsError(), reason, clearNominatedNode)
return
}
// Run "prebind" plugins.
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, nil)
}
sched.handleSchedulingFailure(fwk, assumedPodInfo, preBindStatus.AsError(), SchedulerError, clearNominatedNode)
return
}
//执行bind逻辑
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if err := sched.Cache.ForgetPod(assumedPod); err != nil {
klog.ErrorS(err, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, nil)
}
sched.handleSchedulingFailure(fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, clearNominatedNode)
return
}
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
klog.V(2).InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// Run "postbind" plugins.
fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
// At the end of a successful binding cycle, move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Unlike the logic in scheduling cycle, we don't bother deleting the entries
// as `podsToActivate.Map` is no longer consumed.
}
}()
}
2.1 NextPod
//pkg/scheduler/scheduler.go
// New returns a Scheduler
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
...
sched := newScheduler(
schedulerCache,
extenders,
//NextPod实现
internalqueue.MakeNextPodFunc(podQueue),
MakeDefaultErrorFunc(client, podLister, podQueue, schedulerCache),
stopEverything,
podQueue,
profiles,
client,
snapshot,
options.percentageOfNodesToScore,
)
...
}
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the p.closed is set and the condition is broadcast,
// which causes this loop to continue and return from the Pop().
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait()
}
//可以看出是从activeQ获取数据
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
p.schedulingCycle++
return pInfo, nil
}
2.2 SchedulePod
// newScheduler creates a Scheduler object.
func newScheduler(
cache internalcache.Cache,
extenders []framework.Extender,
nextPod func() *framework.QueuedPodInfo,
Error func(*framework.QueuedPodInfo, error),
stopEverything <-chan struct{},
schedulingQueue internalqueue.SchedulingQueue,
profiles profile.Map,
client clientset.Interface,
nodeInfoSnapshot *internalcache.Snapshot,
percentageOfNodesToScore int32) *Scheduler {
sched := Scheduler{
Cache: cache,
Extenders: extenders,
NextPod: nextPod,
Error: Error,
StopEverything: stopEverything,
SchedulingQueue: schedulingQueue,
Profiles: profiles,
client: client,
nodeInfoSnapshot: nodeInfoSnapshot,
percentageOfNodesToScore: percentageOfNodesToScore,
}
//在这赋值
sched.SchedulePod = sched.schedulePod
return &sched
}
// schedulePod tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError with reasons.
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
//获取最新的Snapshot信息,以此次的snapshot中的node状态为基础执行filter和score逻辑
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
//执行调度器的filter逻辑 节点预选
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: sched.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
//执行score逻辑 节点优选
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
//从所有node中选择score最高的返回
host, err := selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}
2.2.1 findNodesThatFitPod
// Filters the nodes to find the ones that fit the pod based on the framework
// filter plugins and filter extenders.
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
}
// Run "prefilter" plugins.
//1. 执行prefilter plugin
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
//2. 通过snapshot获取node list
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
if !s.IsSuccess() {
if !s.IsUnschedulable() {
return nil, diagnosis, s.AsError()
}
// All nodes will have the same status. Some non trivial refactoring is
// needed to avoid this copy.
for _, n := range allNodes {
diagnosis.NodeToStatusMap[n.Node().Name] = s
}
// Status satisfying IsUnschedulable() gets injected into diagnosis.UnschedulablePlugins.
if s.FailedPlugin() != "" {
diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin())
}
return nil, diagnosis, nil
}
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
//如果当前pod为nominate pod,则直接返回nominate node (已经指定了node就不需要进行调度了)
if len(pod.Status.NominatedNodeName) > 0 {
feasibleNodes, err := sched.evaluateNominatedNode(ctx, pod, fwk, state, diagnosis)
if err != nil {
klog.ErrorS(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
}
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0 {
return feasibleNodes, diagnosis, nil
}
}
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]*framework.NodeInfo, 0, len(preRes.NodeNames))
for n := range preRes.NodeNames {
nInfo, err := sched.nodeInfoSnapshot.NodeInfos().Get(n)
if err != nil {
return nil, diagnosis, err
}
nodes = append(nodes, nInfo)
}
}
//执行filter plugin
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, nodes)
if err != nil {
return nil, diagnosis, err
}
//执行filter extender plguin
feasibleNodes, err = findNodesThatPassExtenders(sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}
2.2.1.1 预选优化
预选优化是节点预选的一部分,位于执行预选的算法之前,优化操作为了解决集群规模过大时,过多地执行预选算法而耗费性能。
优化操作就是计算出筛选出预选节点与集群总节点数达到一个比例值时,就停止执行预选算法,将这批节点拿去执行节点优选。
// numFeasibleNodesToFind returns the number of feasible nodes that once found, the scheduler stops
// its search for more feasible nodes.
//预选优化
func (sched *Scheduler) numFeasibleNodesToFind(numAllNodes int32) (numNodes int32) {
if numAllNodes < minFeasibleNodesToFind || sched.percentageOfNodesToScore >= 100 {
return numAllNodes
}
adaptivePercentage := sched.percentageOfNodesToScore
if adaptivePercentage <= 0 {
basePercentageOfNodesToScore := int32(50)
adaptivePercentage = basePercentageOfNodesToScore - numAllNodes/125
//minFeasibleNodesPercentageToFind是常量,值为5
if adaptivePercentage < minFeasibleNodesPercentageToFind {
adaptivePercentage = minFeasibleNodesPercentageToFind
}
}
numNodes = numAllNodes * adaptivePercentage / 100
//minFeasibleNodesToFind是常量,值为100
if numNodes < minFeasibleNodesToFind {
return minFeasibleNodesToFind
}
return numNodes
}
当集群规模小于100个节点时不进行预选优化,预选优化的最小值就是100。
当percentageOfNodesToScore设置成非正数时,会通过公式50-numAllNodes/125 算出,得出的值如果小于5则强制提升成5,即比例的最小值是5
2.2.1.2 节点预选
当执行完预选优化后就会执行节点预选,节点预选主要是执行一个函数,判定节点是否符合条件,不符合的节点就会被筛选掉,只有符合的节点才会留下来作下一步的节点优选。
// findNodesThatPassFilters finds the nodes that fit the filter plugins.
func (sched *Scheduler) findNodesThatPassFilters(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
diagnosis framework.Diagnosis,
nodes []*framework.NodeInfo) ([]*v1.Node, error) {
//预选优化
numNodesToFind := sched.numFeasibleNodesToFind(int32(len(nodes)))
// Create feasible list with enough space to avoid growing it
// and allow assigning.
feasibleNodes := make([]*v1.Node, numNodesToFind)
if !fwk.HasFilterPlugins() {
length := len(nodes)
for i := range feasibleNodes {
feasibleNodes[i] = nodes[(sched.nextStartNodeIndex+i)%length].Node()
}
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + len(feasibleNodes)) % length
return feasibleNodes, nil
}
errCh := parallelize.NewErrorChannel()
var statusesLock sync.Mutex
var feasibleNodesLen int32
ctx, cancel := context.WithCancel(ctx)
//进行节点预选
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%len(nodes)]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == framework.Error {
errCh.SendErrorWithCancel(status.AsError(), cancel)
return
}
if status.IsSuccess() {
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo.Node()
}
} else {
statusesLock.Lock()
diagnosis.NodeToStatusMap[nodeInfo.Node().Name] = status
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin())
statusesLock.Unlock()
}
}
beginCheckNode := time.Now()
statusCode := framework.Success
defer func() {
// We record Filter extension point latency here instead of in framework.go because framework.RunFilterPlugins
// function is called for each node, whereas we want to have an overall latency for all nodes per scheduling cycle.
// Note that this latency also includes latency for `addNominatedPods`, which calls framework.RunPreFilterAddPod.
metrics.FrameworkExtensionPointDuration.WithLabelValues(frameworkruntime.Filter, statusCode.String(), fwk.ProfileName()).Observe(metrics.SinceInSeconds(beginCheckNode))
}()
// Stops searching for more nodes once the configured number of feasible nodes
// are found.
fwk.Parallelizer().Until(ctx, len(nodes), checkNode)
processedNodes := int(feasibleNodesLen) + len(diagnosis.NodeToStatusMap)
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + processedNodes) % len(nodes)
feasibleNodes = feasibleNodes[:feasibleNodesLen]
if err := errCh.ReceiveError(); err != nil {
statusCode = framework.Error
return nil, err
}
return feasibleNodes, nil
}
func (f *frameworkImpl) RunFilterPluginsWithNominatedPods(ctx context.Context, state *framework.CycleState, pod *v1.Pod, info *framework.NodeInfo) *framework.Status {
var status *framework.Status
podsAdded := false
// We run filters twice in some cases. If the node has greater or equal priority
// nominated pods, we run them when those pods are added to PreFilter state and nodeInfo.
// If all filters succeed in this pass, we run them again when these
// nominated pods are not added. This second pass is necessary because some
// filters such as inter-pod affinity may not pass without the nominated pods.
// If there are no nominated pods for the node or if the first run of the
// filters fail, we don't run the second pass.
// We consider only equal or higher priority pods in the first pass, because
// those are the current "pod" must yield to them and not take a space opened
// for running them. It is ok if the current "pod" take resources freed for
// lower priority pods.
// Requiring that the new pod is schedulable in both circumstances ensures that
// we are making a conservative decision: filters like resources and inter-pod
// anti-affinity are more likely to fail when the nominated pods are treated
// as running, while filters like pod affinity are more likely to fail when
// the nominated pods are treated as not running. We can't just assume the
// nominated pods are running because they are not running right now and in fact,
// they may end up getting scheduled to a different node.
for i := 0; i < 2; i++ {
stateToUse := state
nodeInfoToUse := info
if i == 0 {
var err error
podsAdded, stateToUse, nodeInfoToUse, err = addNominatedPods(ctx, f, pod, state, info)
if err != nil {
return framework.AsStatus(err)
}
} else if !podsAdded || !status.IsSuccess() {
break
}
statusMap := f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
status = statusMap.Merge()
if !status.IsSuccess() && !status.IsUnschedulable() {
return status
}
}
return status
}
这个预选算法会有可能执行两次,这个跟Preempt抢占机制有关系。
第一次执行是尝试加上NominatedPod执行节点预选,NominatedPod指的是那些经过抢占机制预计调度到本节点且实际上还没调度到本节点上的pod,执行这个主要是为了考虑pod的亲和性与反亲和性这种场景的高级调度
第二次则不加NominatedPod,两次都能通过的才算是通过了节点预选。当然当前节点没有NominatedPod,就执行一次算法就够了。
f.RunFilterPlugins>f.runFilterPlugin>pl.Filter
节点预选算法有以下几种
2.2.2 prioritizeNodes
节点优选是从节点预选筛选后的节点执行优选算法算分,汇聚出来的总分供后续“节点选定”时选择。
func prioritizeNodes(
ctx context.Context,
extenders []framework.Extender,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (framework.NodeScoreList, error) {
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(extenders) == 0 && !fwk.HasScorePlugins() {
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{
Name: nodes[i].Name,
Score: 1,
})
}
return result, nil
}
// Run PreScore plugins.
//执行pre score plugin
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
// Run the Score plugins.
//执行score plugin 节点优选
scoresMap, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return nil, scoreStatus.AsError()
}
// Additional details logged at level 10 if enabled.
klogV := klog.V(10)
if klogV.Enabled() {
for plugin, nodeScoreList := range scoresMap {
for _, nodeScore := range nodeScoreList {
klogV.InfoS("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", plugin, "node", nodeScore.Name, "score", nodeScore.Score)
}
}
}
// Summarize all scores.
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
if len(extenders) != 0 && nodes != nil {
var mu sync.Mutex
var wg sync.WaitGroup
combinedScores := make(map[string]int64, len(nodes))
for i := range extenders {
if !extenders[i].IsInterested(pod) {
continue
}
wg.Add(1)
go func(extIndex int) {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Dec()
wg.Done()
}()
prioritizedList, weight, err := extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
klog.V(5).InfoS("Failed to run extender's priority function. No score given by this extender.", "error", err, "pod", klog.KObj(pod), "extender", extenders[extIndex].Name())
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
if klogV.Enabled() {
klogV.InfoS("Extender scored node for pod", "pod", klog.KObj(pod), "extender", extenders[extIndex].Name(), "node", host, "score", score)
}
combinedScores[host] += score * weight
}
mu.Unlock()
}(i)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
}
}
if klogV.Enabled() {
for i := range result {
klogV.InfoS("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", result[i].Name, "score", result[i].Score)
}
}
return result, nil
}
2.2.2.1 RunScorePlugins
// RunScorePlugins runs the set of configured scoring plugins. It returns a list that
// stores for each scoring plugin name the corresponding NodeScoreList(s).
// It also returns *Status, which is set to non-success if any of the plugins returns
// a non-success status.
func (f *frameworkImpl) RunScorePlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) (ps framework.PluginToNodeScores, status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(score, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
//初始化存放分数的map
pluginToNodeScores := make(framework.PluginToNodeScores, len(f.scorePlugins))
for _, pl := range f.scorePlugins {
pluginToNodeScores[pl.Name()] = make(framework.NodeScoreList, len(nodes))
}
ctx, cancel := context.WithCancel(ctx)
errCh := parallelize.NewErrorChannel()
//按预选结果的node并行执行优选算法,得出每个节点分别在各个优选算法下的分数
// Run Score method for each node in parallel.
f.Parallelizer().Until(ctx, len(nodes), func(index int) {
for _, pl := range f.scorePlugins {
nodeName := nodes[index].Name
s, status := f.runScorePlugin(ctx, pl, state, pod, nodeName)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
pluginToNodeScores[pl.Name()][index] = framework.NodeScore{
Name: nodeName,
Score: s,
}
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("running Score plugins: %w", err))
}
// Run NormalizeScore method for each ScorePlugin in parallel.
f.Parallelizer().Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
nodeScoreList := pluginToNodeScores[pl.Name()]
if pl.ScoreExtensions() == nil {
return
}
status := f.runScoreExtension(ctx, pl, state, pod, nodeScoreList)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("running Normalize on Score plugins: %w", err))
}
//并行计算每个节点每个插件加权后的分数
// Apply score defaultWeights for each ScorePlugin in parallel.
f.Parallelizer().Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
// Score plugins' weight has been checked when they are initialized.
weight := f.scorePluginWeight[pl.Name()]
nodeScoreList := pluginToNodeScores[pl.Name()]
for i, nodeScore := range nodeScoreList {
// return error if score plugin returns invalid score.
if nodeScore.Score > framework.MaxNodeScore || nodeScore.Score < framework.MinNodeScore {
err := fmt.Errorf("plugin %q returns an invalid score %v, it should in the range of [%v, %v] after normalizing", pl.Name(), nodeScore.Score, framework.MinNodeScore, framework.MaxNodeScore)
errCh.SendErrorWithCancel(err, cancel)
return
}
nodeScoreList[i].Score = nodeScore.Score * int64(weight)
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("applying score defaultWeights on Score plugins: %w", err))
}
return pluginToNodeScores, nil
}
节点优选的临时结果是存放在一个
map[优选算法名]map[节点名]分数这样的二重map中并行计算是每一个节点顺序执行所有优选插件,然后存放在临时map中
优选计算完毕后再并行计算各个分数加权后的值
// Summarize all scores.
//汇总
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
2.2.2.2 优选算法
fwk.RunScorePlugins>f.runScorePlugin>pl.Score
节点优选算法有如下几种
2.2.3 selectHost
节点选定是根据节点优选的结果求出总分最大值节点,当遇到分数相同的时候则通过随机方式选出一个节点
// selectHost takes a prioritized list of nodes and then picks one
// in a reservoir sampling manner from the nodes that had the highest score.
func selectHost(nodeScoreList framework.NodeScoreList) (string, error) {
if len(nodeScoreList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
maxScore := nodeScoreList[0].Score
selected := nodeScoreList[0].Name
cntOfMaxScore := 1
for _, ns := range nodeScoreList[1:] {
if ns.Score > maxScore {
maxScore = ns.Score
selected = ns.Name
cntOfMaxScore = 1
} else if ns.Score == maxScore {
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
// Replace the candidate with probability of 1/cntOfMaxScore
selected = ns.Name
}
}
}
return selected, nil
}
2.3 Preempt抢占
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle.
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
fitError.Diagnosis.PostFilterMsg = status.Message()
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
这个地方即使抢占成功,pod也不会立马调度到对应节点,而是重新入队,期待下次能够调度成功。
流程:
fwk.RunPostFilterPlugins > f.runPostFilterPlugin > pl.PostFilter > pe.Preempt
func (ev *Evaluator) Preempt(ctx context.Context, pod *v1.Pod, m framework.NodeToStatusMap) (*framework.PostFilterResult, *framework.Status) {
// 0) Fetch the latest version of <pod>.
// It's safe to directly fetch pod here. Because the informer cache has already been
// initialized when creating the Scheduler obj, i.e., factory.go#MakeDefaultErrorFunc().
// However, tests may need to manually initialize the shared pod informer.
podNamespace, podName := pod.Namespace, pod.Name
//拿最新版本的pod,刷新lister的缓存
pod, err := ev.PodLister.Pods(pod.Namespace).Get(pod.Name)
if err != nil {
klog.ErrorS(err, "Getting the updated preemptor pod object", "pod", klog.KRef(podNamespace, podName))
return nil, framework.AsStatus(err)
}
// 1) Ensure the preemptor is eligible to preempt other pods.
//确保抢占者有资格抢占其他Pod
// *看pod是否已有历史的抢占记录pod.Status.NominatedNodeName
// * 无则直接通过 有则需要检查是否该node上有优先级比当前小且有正在删除中的pod
if ok, msg := ev.PodEligibleToPreemptOthers(pod, m[pod.Status.NominatedNodeName]); !ok {
klog.V(5).InfoS("Pod is not eligible for preemption", "pod", klog.KObj(pod), "reason", msg)
return nil, framework.NewStatus(framework.Unschedulable, msg)
}
// 2) Find all preemption candidates.
// 寻找抢占候选者
candidates, nodeToStatusMap, err := ev.findCandidates(ctx, pod, m)
if err != nil && len(candidates) == 0 {
return nil, framework.AsStatus(err)
}
// Return a FitError only when there are no candidates that fit the pod.
if len(candidates) == 0 {
fitError := &framework.FitError{
Pod: pod,
NumAllNodes: len(nodeToStatusMap),
Diagnosis: framework.Diagnosis{
NodeToStatusMap: nodeToStatusMap,
// Leave FailedPlugins as nil as it won't be used on moving Pods.
},
}
// Specify nominatedNodeName to clear the pod's nominatedNodeName status, if applicable.
return framework.NewPostFilterResultWithNominatedNode(""), framework.NewStatus(framework.Unschedulable, fitError.Error())
}
// 3) Interact with registered Extenders to filter out some candidates if needed.
//与注册扩展器进行交互,以便在需要时筛选出某些候选者
candidates, status := ev.callExtenders(pod, candidates)
if !status.IsSuccess() {
return nil, status
}
// 4) Find the best candidate.
//选出最佳的候选者
//选择标准如下
//1.选择一个PBD(PDB全称PodDisruptionBudget,可以理解为是k8s中用来保证Deployment、StatefulSet等控制器在集群中存在的最小副本数量的一个对象)违规数量最少的
//2.选择一个包含最高优先级牺牲者(victims)最小的
//3.所有牺牲者的优先级联系被打破
//4.联系仍存在,最少牺牲者的
//5.联系仍存在,拥有所有最高优先级的牺牲者最迟才启动的
//6.联系仍存在,经排序或随机后,第一个节点
bestCandidate := ev.SelectCandidate(candidates)
if bestCandidate == nil || len(bestCandidate.Name()) == 0 {
return nil, framework.NewStatus(framework.Unschedulable, "no candidate node for preemption")
}
// 5) Perform preparation work before nominating the selected candidate.
//在提名选定的候选人之前,先进行准备工作
//驱逐(实际上是删掉)牺牲pod并拒绝他们再调到本节点上
//把比本pod优先级低的Nominated也清掉,更新这些pod的status信息
if status := ev.prepareCandidate(bestCandidate, pod, ev.PluginName); !status.IsSuccess() {
return nil, status
}
return framework.NewPostFilterResultWithNominatedNode(bestCandidate.Name()), framework.NewStatus(framework.Success)
}
当一个 pod 调度失败后,就会被暂时 “搁置” 处于 pending 状态,直到 pod 被更新或者集群状态发生变化,调度器才会对这个 pod 进行重新调度。
但是有的时候,我们希望给pod分等级,即分优先级。当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod,这样一来就可以保证高优先级 Pod 会优先调度成功。
抢占发生的原因,一定是一个高优先级的 pod 调度失败,我们称这个 pod 为“抢占者”,称被抢占的 pod 为“牺牲者”(victims)。
2.4 Bind
// Bind binds pods to nodes using the k8s client.
func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
klog.V(3).InfoS("Attempting to bind pod to node", "pod", klog.KObj(p), "node", klog.KRef("", nodeName))
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
}
err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})
if err != nil {
return framework.AsStatus(err)
}
return nil
}
可以看到通过client-go进行了bind操作。